What is the temperature outside? Hold on, I’ll check…
Ok, I went outside and felt the air temperature. I think that it is 30C but I’m not very good at telling the temperature when it’s humid out; we’ll say that it’s 30C with a standard deviation of 3C. That is, we wouldn’t be surprised if it was 27C or 33C but we’re confident that it’s not 20C or 40C. Rather than represent the temperature as a number like 30, lets represent it with a Normal Random Variable with mean 30 and standard deviation 3.
>>> T = Normal(30, 3)
We represent this pictorally as follows.

Hopefully you find this representation intuitive. If you’re a math guy you might like the functional form of this:
>>> Density(T)

You’ll see that as x gets away from the mean, 30, the probability starts to drop off rapidly. The speed of the drop off is moderated by 2 times the square of the standard deviation, 18, present in the denominator of the exponent.
We’ll call this curve the prior distribution of T. Prior to what you might ask? Prior to me going outside with a thermometer to measure the actual temperature.
My thermometer is small and the lines are very close together. This makes it difficult to get a precise measurement. I think I can only measure the temperature to the nearest one or two degrees. We’ll describe this measurement noise by another Normal Random Variable with standard deviation 1.5.
>>> noise = Normal(0, 1.5)
>>> Density(noise)

Before I go outside lets think about the value I might measure on this thermometer. Given our understanding of the temperature we expect to get a value around 30C. This value might vary though both because our original estimate of T might be off (the weather might actually be 33C) and because I won’t measure it correctly because the lines are small. We can describe this value+variability as the sum of two random variables
>>> observation = T + noise
Ok, I just came back from outside. I measured 26C on the thermometer; reasonable but a bit lower than I expected. We remember that this measurement has some uncertainty attached to it due to the noise and represent it with a random variable rather than just a number
>>> data = 26 + noise

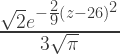
Note how the data curve looks skinnier. This is because its more precise around the mean value, 26. It’s taller so that the area under the curve is equal to one.
After we make this measurement how should our estimate of the temperature change? We have the original estimate, 30C +- 3C, and the new measurement 26C +- 1.5C. We could take the thermometer’s reading because it is more precise but this doesn’t use the original information at all. The old measurement still has useful information and it would be best to cleanly assimilate the new bit of data (26C+-1.5C) into our prior understanding (30C +-3C).
This is the problem of Data Assimilation. We want to assimilate a new meaurement (data) into our previous understanding (prior) to form a new and better-informed understanding (posterior). Really, we want to compute
<<T_new = T_old given that observation == 26 >>
We can do this in SymPy as follows
>>> T_new = Given( T , Eq(observation, 26) )
This posterior is represented below both visually and mathematically

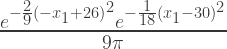
The equation tells us that the temperature, here represented by 
We notice that the posterior is a judicious compromise between the two, weighting the data more heavily because it was more precise. The astute statistician might notice that the variance of the posterior is lower than either of the other two (the blue curve is skinnier and so varies less). That is, by combining both measurements we were able to reduce uncertainty below the best of either of them. It’s worth noting that this solution wasn’t built into SymPy-stats or into some standard probabilistic trick. This is the answer given the most basic and fundamental rules.
The code for this demo is available here. It depends this statistics branch of SymPy and on matplotlib for the plotting .
Data assimilation is a very active research topic these days. Common applications include weather prediciton, automated aircraft navigation, and phone-gps navigation.
Phone/GPS navigation is a great example. Your phone has three ways of telling where it is; cell towers, GPS satellites, and the accelerometer. Cell towers are reliable but low precision. GPS satellites are precise to a few meters but need some help to find out generally where they are and update relatively infrequently. The accelerometer has fantastic, real-time precision but is incapable of large scale location detection. Merging all three types of information on-the-fly creates a fantastic product that magically tells us to “turn left here” at just the right time.

I was struck by your unconventional choice of variance over standard deviation when specifying the distribution. A quick survey of Numpy, R, Matlab and Mathematica shows that all use standard deviation when specifying the distribution.
I chose Normal(mean, variance) because that’s how it’s done more often in mathematics texts/papers.
I didn’t realize all the other packages used Normal(mean, std) though! I’ve changed my code and may get around to editing the blog post today or tomorrow. Thanks for the input!
Blog post fixed as well.
Thanks for your input Gary!
Pingback: Multivariate Normal Random Variables | sympy-stats
This was nicely presented! I’m curious about Given( T , Eq(observation, 26) ). I would have expected (without having the docs in front of me) to have seen Given(observation, data).
Thanks!
The first argument in Given is the target expression (I want to know arg1 given that arg2).
The data!=26 confusion is due just to an odd naming convention on my part. The intuitive meaning of a variable name like data is whatever I measured on the thermometer. Instead, I define data = 26 + noise so that it represents the measurement on the thermometer plus my uncertainty a better name might be distribution_of_uncertain_measurement. This variable gives us the nice plot in the second figure.
Observation and data are a bit redundant.
observation == T + noise
data == 26 + noise
So if we claim that observation==data we’ve essentially made the claim that T==26 regardless of what the measurement noise is. I decided this would be a good test of my code. It isn’t the sort of statement I had in mind while coding but should hopefully still work.
>>> T = Normal(30, 2)
>>> E(T)
30
>>> var(T)
2
>>> noise = Normal(0,1)
>>> observation = T+noise
>>> data = 26+noise
>>> Tnew = Given(T, Eq(observation, data))
>>> E(Tnew)
26
>>> var(Tnew)
0
>>> P(Eq(Tnew, 26)) # Should be one
# Integral hangs unfortunately
>>> P(And(Tnew>25.9, Tnew<26.1))
1
I’ve just reread this and am struck by just how cool this stuff is. I’m sure I’ll find a way to use these data assimilation concepts for something! If you are ever looking for something to write about, some more thoughts and real-world uses on this would be an interesting read (and how to replicate this in SymPy, of course!).
Hi, I read this 2 years ago and I just found it again. It is really cool stuff. Are there any plans to move this forward and merge it with sympy main repo?
Thanks for the kind words. This work was merged a couple years ago and should be available in any decently modern version of sympy.